Motivazione
Di recente ho avuto la necessità di creare con R un istogramma per rappresentare la distribuzione empirica congiunta di 2 variabili, nella fattispecie i rendimenti di 2 titoli con lo scopo di mostrare lo shape della distribuzione. In Excel è infatti possibile creare l’istogramma per una variabile, ma non per due congiuntamente. Prima di approcciare direttamente il problema, ho googlato un po’ l’argomento senza però trovare una soluzione “pronta all’uso” pienamente soddisfacente (ho trovato diverse soluzioni ma ognuna aveva qualche problema). Di seguito descrivo come ho risolto il problema, mentre il risultato è l’immagine qui sotto: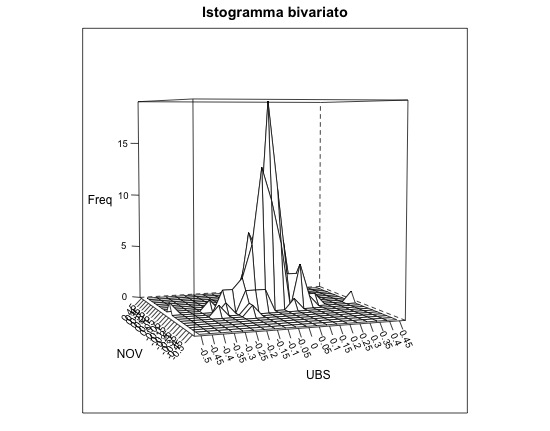
Soluzione
Personalmente (non posso certo considerarmi esperto di R), la maggiore difficoltà nel generare un simile grafico in R è stata la creazione della matrice di frequenze congiunte, ossia gli incroci delle frequenze della variabile nelle N classi definite. Tuttavia, andando per ordine:
#1: ho scaricato i dati da Yahoo Finance, nella fattipsecie mensili (ma la frequenza in questo caso non è influente). Vedi qui la procedura. Ovviamente ciò che mi interessa sono i prezzi di chiusura. Clicca qui per vedere il file che ho utilizzato, dove la prima colonna contiene le date, la seconda i prezzi di chiusura mensili del titolo UBS e la terza colonna i prezzi di chiusura mensili del titolo Novartis.
#2: ho importato i dati (formato csv) dei prezzi scaricati al punto #1 con il semplice comando.
price <- read.csv("~percorso/nomefile.csv",sep=";",header=TRUE)
#3: a partire dai prezzi, genero i rendimenti con questo codice (è un modo di generare i rendimenti, non l’unico possibile)
matriceprezzi=as.matrix(price[,2:3]) differenza=diff(matriceprezzi) rendi=differenza / price[1:length(price),2:3]
#4: creo le classi, generando una sequenza incrementale dal rendimento minimo in assoluto (tra i rendimenti dei due titoli) a quello massimo in assoluto tra le due serie. L’entità dell’incremento che uso è di 0.05 ma potete impostarlo come preferite, ottenendo di conseguenza classi più o meno ristrette. Il numero di classi che ottenete ovviamente dipende dalla dispersione dei rendimenti e dall’entità dell’incremento. Nel mio caso, il rendimento minimo osservato tra UBS e Novartis è -50.41021%, mentre il rendimento massimo osservato è +44.64475%. La classe 1 perciò comprenderà i rendimenti compresi tra -50.41021% e 49.91021% più vicini al primo valore, la classe 2 quelli compresi tra 49.91021% e 49.41021% più vicino al primo valore, e così via.
min<-min(rendi) max<-max(rendi) classi<-seq(min,max, by=0.05) length(classi)
#5: dopo aver creato le classi al punto #4, dobbiamo assegnare ciascuno dei rendimenti della nostra serie alla rispettiva classe di appartenenza. Denominerò qui le due variabili “var1” e “var2” (nel mio esempio sarebbero UBS e Novartis). Con il seguente comando creo due vettori (“cvar1” e “cvar2”), di lunghezza pari al vettore che contiene i rendimenti (quindi le colonne 1 e 2 della matrice dei rendimenti), che contiene il numero della classe a cui appartiene il rendimento. Nel mio caso, se il primo redimento osservato per UBS è -49.5000%, il primo valore del vettore classe per UBS sarà 2 (vedi classi sopra), e così via. Il codice è
cvar1<-findInterval(rendi[,1],classi) cvar2<-findInterval(rendi[,2],classi)
#6: creo una matrice quadrata vuota, da riempire (punto #7) con i le frequenze congiunte per ogni classe dei rendimenti dei due titoli. Le dimensioni della matrice dipendono evidentemente dal numero di classi. Chiamo questa matrice “hist” e la genero con questo comando
hist<-matrix(nrow=length(classi),ncol=length(classi))
#7: per riempire la matrice, utilizzo una doppia loop (nested loop). Questo è il vero cuore del codice. Per ogni riga i della matrice “hist” (i è compreso tra 1 e il numero delle classi create), la loop crea j colonne (anche j ovviamente è compreso tra 1 ed il numero di classi create, perché la matrice “hist” è quadrata). Ogni colonna j della riga i (quindi stiamo parlando di un valore) è calcolato con la funzione “sum” e rappresenta il numero di casi in cui cvar1=i e simultaneamente cvar2=j (nel codice questa condizione è espressa come “cvar1==i&cvar2==j”). Quindi nel mio caso, se i=1 e j=1, avrò il numero di frequenze dell’abbinamento in cui i rendimenti sia di UBS che di Novartis appartengono alla classe 1. Se i=1 e j=2, avrò il numero di frequenze dell’abbinamento in cui i rendimenti di UBS appartengono alla classe 1 mentre quelli di Novartis sono nella classe 2. E così via… Il codice è
for(i in 1:length(classi)){
for(j in 1:length(classi)){
hist[i,j]<-c(sum(cvar1==i&cvar2==j))
}
}
#8: a questo punto, aggiungo il nome a righe e colonne della matrice “hist”. I nomi saranno di fatto i rendimenti che rappresentano le classi, arrotondati al secondo decimale.Il relativo codice è
colnames(hist)=round(classi,2) rownames(hist)=round(classi,2)
#9: infine non resta che creare il grafico, nella fattispecie l’istogramma. Ci sono diverse funzioni in R, che a livello grafico è molto versatile. Nel mio esempio uso la funzione “wireframe”. Per utilizzarla dobbiamo caricare il pacchetto “lattice”. Ci sono poi alcune opzioni di visualizzazione con cui potete giocare, tuttavia non entro nei dettagli qui.
library(lattice) wireframe(main="Istogramma bivariato", hist, screen = list( z=20,x = -85),ylab="var2",xlab="var1",zlab="Freq",scales = list(x=list(arrow=FALSE,rot=-65,distance=1),y=list(arrow=FALSE,rot=55,distance=1),z=list(arrow=FALSE)))
Di seguito, il codice completo per questo istogramma. Ricordate che il codice qui riportato vale per il file di dati strutturato come sopra (colonna 1=data, colonna 2=prezzo 1, colonna 3=prezzo 2). Ho cercato di rendere l’esempio il più generale possibile, nonostante si tratti di un caso applicato alla distribuzione congiunta dei rendimenti di 2 titoli partendo dai prezzi degli stessi.
price <- read.csv("~percorso/nomefile.csv",sep=";",header=TRUE)
matriceprezzi=as.matrix(price[,2:3])
differenza=diff(matriceprezzi)
rendi=differenza / price[1:length(price),2:3]
min<-min(rendi)
max<-max(rendi)
classi<-seq(min,max, by=0.05)
length(classi)
cvar1<-findInterval(rendi[,1],classi)
cvar2<-findInterval(rendi[,2],classi)
hist<-matrix(nrow=length(classi),ncol=length(classi))
for(i in 1:length(classi)){
for(j in 1:length(classi)){
hist[i,j]<-c(sum(cvar1==i&cvar2==j))
}
}
colnames(hist)=round(classi,2)
rownames(hist)=round(classi,2)
library(lattice)
wireframe(main="Istogramma bivariato", hist, screen = list( z=20,x = -85),ylab="var2",xlab="var1",zlab="Freq",scales = list(x=list(arrow=FALSE,rot=-65,distance=1),y=list(arrow=FALSE,rot=55,distance=1),z=list(arrow=FALSE)))
